





Record pools have been a crucial part of the Constellix suite since it was first conceived four years ago. But a lot of our clients have no idea they exist. That, or they have a vague understanding of what pools are but don't think they can help them.
Pools were created to make your job easier. Specifically, DNS load balancing which manages how traffic flows to multiple endpoints. And best of all, pools can be combined with a bunch of our other services like Failover, GTD, and our new performance load balancing service to make some cool load balancing configurations.Don't want to read about it? Watch the video:
How do record pools work?
Think of a pool as a group of records.As you know, a single DNS record points to a single IP address. Whereas, a record pool cycles through multiple IP addresses in a round robin fashion. In this case, a group of DNS records. Like this:

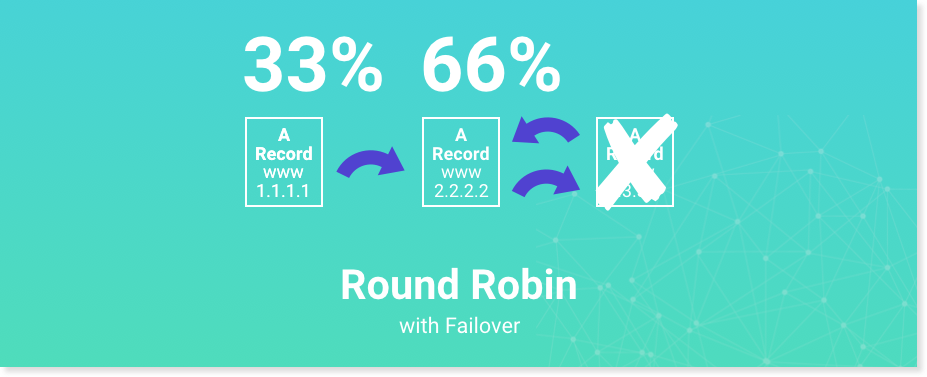
Round Robin
Does "round robin" sound familiar? It's actually an old DNS configuration that consists of multiple records with the same name, but each one points to a different IP address. When the domain is queried, users are alternately answered by each of the records.We made it a whole lot simpler with record pools. Instead of creating a record for each IP address, you can create a single record pool containing all the IP's you want that record to point to. You would then apply the pool to the desired record. You can even apply a single pool to multiple records. And if when you make changes to the pool, and any record with the pool applied will be updated.Pools also allow for weighted round robin, which changes how often an IP is returned in a pool. All you have to do is add weights to the IP's in the pool. Say you give all but one IP a weight of 10. The last IP gets a weight of 20. The pool would return the last IP twice as often as any other IP.You can use weighted round robin for feature rollouts or test new infrastructure.
Failover DNS
Round Robin
One of the key differentiators between traditional DNS methods and record pools is how each uses Failover. Let's take our round robin example from earlier but add a failover rule for each record.

If you have each IP pointing to another in a circular fashion, you won't have this issue. But if you have more than one IP pointing to another, what can happen is this:
Regardless of whether an IP is up or down, that record is still included in the round robin configuration. Every time our active failover record is returned in the pool, it will point to another IP thus doubling the frequency that IP is returned.This might not be an issue for you, but if you are worried about increased the load on that IP then you may want to consider switching to record pools.
Pool Failover
Since we're only dealing with a single record with a group of IP addresses, we don't have to return the IP that is down. That means, if our 3.3.3.3 IP is down, we will only return 1.1.1.1 and 2.2.2.2 each 50% of the time.

You can even failover from one pool to another. Just specify how many IP's need to have available in the pool for it to be considered "up".

But pools fail short on one thing... If you have a failover configuration that isn't cyclical (like the example we showed for round robin failover) you would want to stick with round robin records. That way you can specify exactly which IP(s) you want to failover to, rather than cycling through a list of available IP's.
Performance Load Balancing
Pools open the door for a wealth of possibilities, like performance load balancing. We recently released a new service that can be applied to pools that returns the fastest responding IP in a pool. We call it ITO (Internet Traffic Optimization).

You can use ITO pools to load balance across multiple cloud providers, CDN services, web servers, and so much more. A word of advice, we recommend using ITO pools only when you have multiple systems in a single region. Why,you ask?

Well, let's say you have a handful of systems scattered across the globe. If you put them all in an ITO pool, our monitoring nodes are taking global averages of the load times to your systems. This is useless if you want to reduce load times. Instead, we suggest that you only use ITO when you have multiple systems in a region. Otherwise, use GTD which automatically routes users to a system in their region.You could also use GeoProximity with failover, more on that here.If you are a candidate for ITO pools, then we recommend that you also enable GTD. This way, you can create region-specific ITO pools, like so:

Bonus Round!
This is just the beginning of what Constellix record pools are capable of. Since they can be combined with so many of our other services, there are hundreds of use cases you can solve with pools. Take this one, suggested by one our clients:
I have a network of servers in Asia-Pac and I want to answer mobile users with the fastest cloud provider in their region.
This is a three part question:
- A region-specific rule for Asia-Pac
- Route users to the fastest cloud provider
- Only for mobile users
To solve this, you would create an ITO record pool for Asia-Pac. Enable the Global Traffic Director and create an Asia-Pac record that uses that ITO pool we made. Then create an IP Filter that uses the ASN's of mobile carriers in the area.All mobile networks register a physical address to the IP addresses they assign to their mobile devices. So you just need to find the ASN's for those providers, and voila... only mobile traffic in Asia-Pac.

Need better DNS?
We can help.
• Configure with ease
• Prevent DDoS attacks
• Monitor your domains
• Optimize site traffic
• Enhance domain performance
• Free POC Account + Demo
BOOK FREE DEMO
Constellix DNS News








Sign up for industry news and insights. It'll be worth it.
Sign up for news and offers from Constellix and DNS Made Easy



